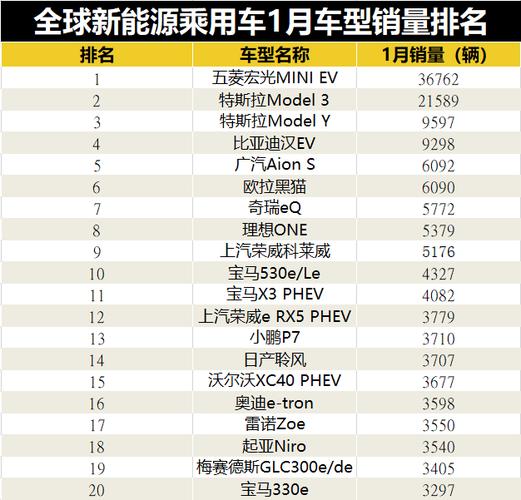
国内首份大模型安全实践报告出炉:大模型短板如何补齐
经过一年多的“野蛮生长”,大模型的应用正在聚沙成塔,安全问题也随之引发关注。2024世界人工智能大会暨人工智能全球治理高级别会议发表的《人工智能全球治理上海宣言》明确提出,要确保其发展过程中的安全性、可靠性、可控性和公平性。
目前,针对大模型的安全评测绝大多数是针对内容类场景,对智能体等高级应用仍是空白区。昨日(5日)下午,《大模型安全实践(2024)》白皮书发布,这是国内首份“大模型安全实践”研究报告,从安全性、可靠性、可控性等维度提供技术框架。
大模型仍无法做出专业决策
近两年来,大模型的进步有目共睹,从本届WAIC的现场来看,大模型在智能涌现能力上提升明显,从初级的语言对话到如今多模态、具身智能的发展趋势,不难看出大模型从规模化迈向产业化。
但是在产业化过程中,业界人士也逐渐发现了大模型的“短板”:泛化能力强但专业能力差,还有长期诟病的幻觉问题。即便是OpenAI最强的大模型GPT-Turbo,依然避免不了事实性错误的局限。
“特别是要求严谨的行业中,我们发现大模型的幻觉问题和缺乏复杂推理的问题非常严重。”蚂蚁集团大模型应用部总经理顾进杰安全实验室首席科学家王维强举例说,大模型对专业领域知识图谱的学习有限,在实际使用过程中得谨慎对待。尤其是金融、医疗等领域对模型输出的专业性和准确性要求极高,“很多医疗的知识不是在书本里,都是在很多医生的脑袋中,大模型就没有办法做复杂的专业决策”。
特别是Transformer架构成为主流后,以此为基础的大模型在泛化能力突飞猛进,但“智能涌现”的能力依然是处于“黑盒”中,人类无法控制其生成的结果,因此造成专业能力进步缓慢。即便是OpenAICEOSamAltman也坦言,GPT-4的专业性仅相当于专业人士的10%—15%。
对此,白皮书总结大模型发展在当下面临的技术、个人、企业和社会四大挑战:大模型技术存在自身缺陷,包括生成内容不可信、能力不可控以及外部安全隐患等问题,带来诸多风险挑战,比如生成“幻觉”问题影响生成内容的可信度;在个人层面,大模型挑战广泛涉及信息获取、公平正义、人格尊严、个人发展以及情感伦理等多个重要维度,同时加剧了“信息茧房”效应;在企业层面,大模型面临用户隐私与商业秘密泄露、版权侵权及数据安全等多重风险挑战;在社会层面,大模型的广泛应用不仅冲击就业市场、扩大数字鸿沟,还可能危及公共安全与利益。
安全、可靠、可控是三大红线
那么,什么样的大模型在应用过程中能称之为安全?“安全、可靠、可控,是人工智能的三大红线。”中国信通院华东分院人工智能事业部主任常永波认为,国内首份大模型安全实践报告出炉:大模型短板如何补齐这三方面缺一不可。
他介绍,安全性意味着确保模型在所有阶段都受到保护,包含了数据安全、应用安全、内容安全、伦理安全、认知安全等诸多方面。可靠性要求大模型在各种情境下都能持续地提供准确、一致、真实的结果,包含模型的鲁棒性(异常情况下能否运行)、真实性、价值对齐。而可控性关乎模型在提供结果和决策时能否让人类了解和介入,可根据人类需要进行调适和操作,包含大模型的可解释研究、大模型的指令遵循能力、安全检测和水印追溯。
常永波表示,国内头部厂商走得比较靠前,蚂蚁、商汤等围绕安全和治理都有系统化的技术指标。而个别公司急于在大模型商业化过程中抢占市场,未能配备相应“安全防护”,如未规范标注和安全自测,会在企业应用和社会治理过程中留有隐患。
“目前,大模型的安全评测绝大多数是针对内容类场景,随着大模型技术快速发展和广泛应用,对智能体这类复杂大模型应用架构和未来通用AGI(通用人工智能)的评估是当下面临的挑战。”常永波认为,以智能体为核心的检测,是大模型安全不可或缺的一环。
记者了解到,上届WAIC“镇馆之宝”蚁天鉴在今年推出2.0版本,新增的“测评智能体”可针对大模型的内在神经元进行“X光扫描”来做探查和判断。“能让技术人员直观感受大模型内部在发生什么、定位可能引发风险的神经元、并进行编辑修正,从而在模型内部治理幻觉,实现从源头识别和抑制风险。”蚂蚁集团安全内容智能负责人赵智源介绍,蚁天鉴如今还新增了“AI鉴真”技术如今的“AI鉴真”技术可,可以快速精准鉴别图像、视频、音频、文本内容的真伪,图像识别准确率99.9%。









嘉辉
这家伙太懒。。。
- 暂无未发布任何投稿。